Happy TSQL Tuesday and thank you to Kendra Little (b|t) for hosting.
It depends: Interviewing anti-pattern
“It depends.”
Such a good and frequent DBA answer. Short, succinct and as frequently used as “best practice”. Also, it’s an interviewing anti-pattern. When left alone or paired with a complaint about not having enough information it is a sign of intellectual laziness and a bad mark in my interviewing grade book. It’s fine as the start of a discussion, but not as an answer.
In the last interview panel I was part of my co-worker gave his favorite Fermi question. How long would it take a bowling ball dropped off the side of a boat to reach the bottom of the deepest part of the ocean. I’ve heard this question in the past and most interviewees give an “It depends” or other similar “not enough information” answer. While true as there are unknown factors and they probably don’t have all the information they need to answer, it is not a good sign if they aren’t willing to try working through the problem. Our latest hire (he started this week) took a bit to think and then began to puzzle it out, using some estimates for the rate of fall and the depth of the deepest part of the ocean. After a bit of pen and paper calculation he gave us an answer. Now it wasn’t 2 hours and 20 minutes, but that doesn’t matter. We weren’t looking for accuracy here, we were looking for though process and he nailed that.
WITH XMLNAMESPACES (
DEFAULT N’http://schemas.microsoft.com/sqlserver/2004/07/showplan’
)
, TextPlans
AS (SELECT CAST(detqp.query_plan AS XML) AS QueryPlan,
detqp.dbid
FROM sys.dm_exec_query_stats AS deqs
CROSS APPLY sys.dm_exec_text_query_plan(
deqs.plan_handle,
deqs.statement_start_offset,
deqs.statement_end_offset
) AS detqp
),
QueryPlans
AS (SELECT RelOp.pln.value(N’@EstimatedTotalSubtreeCost’, N’float’) AS EstimatedCost,
RelOp.pln.value(N’@NodeId’, N’integer’) AS NodeId,
tp.dbid,
tp.QueryPlan
FROM TextPlans AS tp
CROSS APPLY tp.queryplan.nodes(N’//RelOp’)RelOp(pln)
)
SELECT qp.EstimatedCost
FROM QueryPlans AS qp
WHERE qp.NodeId = 0;
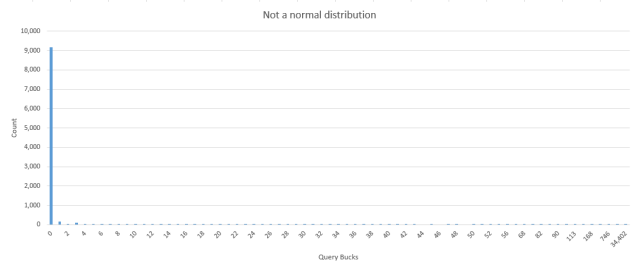
Rounding to zero decimals and subtotaling the costs leaves me with a less than normal distribution. 93%, or over 9,100, plans have a rounded cost of 0 and 95% of the plans are 1 or less query bucks, to use the popular term for cost. Leaving the Cost Threshold For Parallelism at 5 covers 97% of the plans I returned.
These plans are from a SQL Server 2008 R2 SP3 instance that runs a version of Microsoft Dynamics. The MS Dynamics team knows their product issues a bunch of really small queries and recommend a Max Degree of Parallelism of 1. In my case there is one query plan with a cost of 34,402 query bucks that a MAXDOP = 1 can’t afford. Increasing the MAXDOP from 1 while keeping the Cost Threshold at 5 will keep all of my little queries running in their single threaded paradise while allowing some infrequent biguns to spread their lovely wings across a few more threads. My Cost Threshold For Parallelism is set to 5 and I hope to never have to defend my settings in a dark alley with Erik Darling.
This month we have Jorge Segarra (B|T) hosting the T-SQL Tuesday with the topic of Power BI.
Hey data pros, people don’t want to look at your data in tables or result panes. They want charts, graphs and pretty pictures, right? To do that you need Power BI. Just look at this amazing stuff you can do with it. Seriously, go over to Jason Thomas’ site and check it out.
Now the danger of any BI is that data is distilled and as anyone with a pot still can tell you it doesn’t always come out so great and even when it does come out great, it might not be the best stuff for you. An older friend of mine once told me a story about his military service in WWII. Out of boredom they graphed and acyronymized their soda pop consumption. One day, their superior was giving a tour of their office and showed off said chart and everyone nodded in appreciation and utter ignorance. This could easily happen in any business with creative/bored developer and just a bit of time. For example here, I took a bunch of meaningless data, loaded it into Power BI and spit out some charts that would make an exec swoon.
Now I’m sure there are some very valid use cases for BI and implementations of Power BI. Just make sure you know what you’re sipping. Just because you can visualize data doesn’t always mean you should. The most important aspect of BI is that it solves a business question/problem, you know the B part of BI.
The Job Activity Monitor and the View History option are just fine in SQL Server Management Studio, but sometimes you want to run a query to look at the all the successful backups you’ve run.
Don’t be dreary, get to the query.
SELECT
s.database_name,
m.physical_device_name,
CAST(CAST(s.backup_size / 1000000 AS INT) AS VARCHAR(14)) + ' ' + 'MB' AS bkSize,
CAST(DATEDIFF(second, s.backup_start_date,
s.backup_finish_date) AS VARCHAR(4)) + ' ' + 'Seconds' TimeTaken,
s.backup_start_date,
CAST(s.first_lsn AS VARCHAR(50)) AS first_lsn,
CAST(s.last_lsn AS VARCHAR(50)) AS last_lsn,
CASE s.[type]
WHEN 'D' THEN 'Full'
WHEN 'I' THEN 'Differential'
WHEN 'L' THEN 'Transaction Log'
END AS BackupType,
s.server_name,
s.recovery_model
FROM msdb.dbo.backupset s
INNER JOIN msdb.dbo.backupmediafamily m ON s.media_set_id = m.media_set_id
WHERE s.database_name = 'ImportantDB' /*Remove this line for all the databases*/
and s.backup_start_date > DATEADD(d,-1,GETDATE()) /*How far do you want to go back? This returns 1 day of data */
ORDER BY backup_start_date DESC, backup_finish_date
GO
We have two tables here, backupset and backupmediafamily. The backupset does most of the heavy lifting giving you the pertinent info like database name, how big the backup is, how long it took, when the backup started, what kind of back up it is and then some.
msdb.dbo.backupset,”Contains a row for each backup set. A backup set contains the backup from a single, successful backup operation. RESTORE, RESTORE FILELISTONLY, RESTORE HEADERONLY, and RESTORE VERIFYONLY statements operate on a single backup set within the media set on the specified backup device or devices.”
And we only bring in backupmediafamily for the physical_device_name field, a.k.a. the file path and file name of your backup.
msdb.dbo.backupmediafamily “Contains one row for each media family. If a media family resides in a mirrored media set, the family has a separate row for each mirror in the media set.”
You want to see some results? Go run this script you pulled off the internet on your nearest production server. What could possibly go wrong. But really, if you are a good and curious DBA/DBA in training/DBA-curious dev/etc. start with just looking at the msdb.dbo.backupset table.
It’s T-SQL Tuesday, the blog party founded by Adam Machanic (blog|@AdamMachanic) and this month hosted by Robert Davis (blog|@SQLSoldier). The topic, Be the Change.
Start of the New Year is a great time to Be the Change. You could do that by donating to Mercy Corps (full disclosure: my employer) with their familiar tag line Be the change.
You could also do it by digging into data changes, how it changes, where it changes and why it changes. One of my more interesting data changes is with an XML shred. It starts off with a download from an exchange rate API, saving the XML file, shredding it into a tabular format and uploading it to a table. The point I find most interesting is the XML shred.
The below XML has data nested in different levels that requires the nodes method to join them together. The nodes method accepts a XML string and returns a rowset. That rowset can then be used with CROSS APPLY to effectively link your way down.
nodes (XQuery) as Table(Column)
The tabular format I need requires data from 3 different levels of this XML gob and I need to wade through 5 “tables” to get there.
SELECT
mainT.mainC.value('(base_currency/text())[1]','VARCHAR(3)') AS baseRate
, quoteT.quoteC.value('(currency/text())[1]','VARCHAR(3)') as exchangeRate
, quoteT.quoteC.value('(date/text())[1]','VARCHAR(40)') as oDate
, CONVERT(DATETIME,LEFT(REPLACE(REPLACE(quoteT.quoteC.value('(date/text())[1]','VARCHAR(40)') ,'T',' '),'+','.'),23),120) as cDate
, quoteT.quoteC.value('(ask/text())[1]','FLOAT') AS ask
, quoteT.quoteC.value('(bid/text())[1]','FLOAT') AS bid
, epT.epC.value('(date/text())[1]','VARCHAR(40)') AS requestDate
FROM @xml.nodes('/response') mainT(mainC)
/*mainT = main table, mainC = main column*/
CROSS APPLY mainT.mainC.nodes('meta') as metaT(metaC)
CROSS APPLY metaT.metaC.nodes('effective_params') as epT(epC)
/*ep = effective_params*/
CROSS APPLY mainT.mainC.nodes('quotes') as quotesT(quotesC)
CROSS APPLY quotesT.quotesC.nodes('quote') as quoteT(quoteC)
In the beginning of the FROM line I am grabbing the “response” line from @xml (a variable that I loaded the XML file into) and returning the main table/column, referred to as mainT(mainC). In the next line I join to that row set via a CROSS APPLY the “meta” table and so on and so for to get through the “effective_parms”, “quotes” and “quote”. Great naming there, watch for the “s”.
You can see back in the SELECT section I used the mainT.mainC.value to pull the base_currency column. Each rowset returned by the nodes function can be used in the SELECT.
There is also this little bit of fun to change a datetime stored as a string with a “T” in it, “2016-01-11T12:30:04+0000” to a more respectable format that will insert nicely.
As a data professional this is rather embarrassing, but a beer broke my database. I didn’t spill a pint on the server or drop a table in an inebriated fat finger. A fine beer called Paddle Trail Ale by Sierra Nevada AND Crux broke my database on another site I run because of my poor planning. Taking a quick step back, many years of being responsible for maintaining data for others led me to wanting to maintain and visualize my own data. I’ve been drinking, brewing and collecting beer for quite a while so it only made sense (to me) to create a database and begin to chart out my own consumption. Thus beerintelligenceproject.com was born.
Who selected these data types?
When I laid out how data would be organized for this site I failed to take into account that brewers like to hang out with brewers. Probably has something to do with the jovial and friendly product they produce. Collaboration beers are nothing new and I’ve had my fair share of them (Thank you Widmer), but somehow when I went around to designing the table to hold beers I only allotted for a single brewery. There are other beer advocating sites around that have a similar problem and make use of a notes field. I don’t even have that. Just a lone key to a brewery table. I was forward thinking enough to allow for multiple styles as sometime one can’t tell the difference between a Russian Imperial Stout and a Kölsch. Not saying I’ve had the conundrum, but I’m sure someone has.
Now after several hundred beers it is time to refactor my database. The data model needs to adapt, which will cascade down to the queries populating the charts needing to change. This will not be a trivial change. I think I need a beer.
#TSQL2sDay, hosted by Jen McCown (b/t) on strategies for managing an Enterprise.
Managing an enterprise is all about consistency. The best tools and policies out there aren’t going to do you a bit of good if you and your team/coworkers/underlings/minions don’t execute them in a consistent method. Now, is that consistent, consistant or consestent? Good thing we have an enterprise tool like spell check here.
Companies like Idera, RedGate and others have sets of sweet tools to help manage and maintain your enterprise. I’ve used some of them and have been happy with the products, but had several cases where SQL servers broke or didn’t perform up to their expectations. There was powerful hardware, there was monitoring with all the flashing lights and alerts you could ask for, but there wasn’t consistently followed policies and procedures. Writing policies and procedures suck, but it is the necessary task that will save you and your team/coworkers/underlings/minions from being thrown into the tank containing sharks with frickin’ laser beams on their heads.
Instances spread across several continents, time zones and languages can be difficult to manage, especially when your team is also distributed across those three variables. As a good sized enterprise we were able to bring in a suite of enterprise tools from Idera. The wizards were clicked through, lights flashed, alerts alarmed and we were in control of our enterprise…for about 5 minutes. This distributed team did not communicate well. We did not write consistent procedures nor follow consistent policies. We failed as a team and our enterprise reflected this.
As an enterprise of one in my current role I have a much easier time enforcing documentation requirements and adherence to policy. Consistency is still important as I do like going on vacation now and then. Without enterprise documentation how is anyone going to be able to fill in and show my boss how replaceable I am?
What are key parts of my consistent enterprise management?
Ola – Because Ola.
Wiki – Our internal IT spot for documentation, policies and procedures Standard Alerts
HTML formatted table for your SQL alerts or reports
Alerts and reports in plain text are the easiest to setup, fastest to render and smallest to send so why should you bother with HTML formatting? Believe it or not your time and server/network load are not the top concern (or any concern) for most if not all of your users. They want emails showing up looking nice. One look at this example will show I didn’t my degree in design and I have no sense of style, but the structure is there for you to choose your own color pallet to please your users.
When emails look like this, who can ignore them?
I scraped some data from Twitter to load a test table and did a quick sum to see who is the top tweeter in a arbitrary span of time.
If your instance is set up to run msdb.dbo.sp_send_dbmail you should be able to run the script for an example.
CREATE TABLE #testData (rowNumber INT IDENTITY(1,1), person VARCHAR(30), tweets VARCHAR(140))
INSERT INTO #testData (person, tweets) VALUES ('Jes Borland @grrl_geek','45 minute run in 65℉ wiith 100% humidity. Had to work for that one.')
INSERT INTO #testData (person, tweets) VALUES ('Jes Borland @grrl_geek','Awwww yeah, finally got the domain name I wanted for a running blog.')
INSERT INTO #testData (person, tweets) VALUES ('Jes Borland @grrl_geek','I have a script for that.')
INSERT INTO #testData (person, tweets) VALUES ('Jes Borland @grrl_geek','I say that a lot these days. It''s nice to be able to.')
INSERT INTO #testData (person, tweets) VALUES ('Jes Borland @grrl_geek','If Saturday is for doing nothing useful, I''ve succeeded.')
INSERT INTO #testData (person, tweets) VALUES ('Jes Borland @grrl_geek','I''ll always love string cheese.')
INSERT INTO #testData (person, tweets) VALUES ('Jes Borland @grrl_geek','Ready for lunch! (It''s 9:39 am. Ooops.)')
INSERT INTO #testData (person, tweets) VALUES ('Jes Borland @grrl_geek','Scheduled carpet cleaning. I''m officially done with all adult duties for the day.')
INSERT INTO #testData (person, tweets) VALUES ('Jes Borland @grrl_geek','TO THE CLOUD!')
INSERT INTO #testData (person, tweets) VALUES ('Jes Borland @grrl_geek','To the driving range!')
INSERT INTO #testData (person, tweets) VALUES ('Jes Borland @grrl_geek','When I stand outside I sweat. We have 3 cubic feet of river rock to move. Today is going to suck.')
INSERT INTO #testData (person, tweets) VALUES ('Grant Fritchey @Gfritchey','Checking out, then off to #sqlcruise')
INSERT INTO #testData (person, tweets) VALUES ('Grant Fritchey @Gfritchey','Got my feet into the Med. I''m happy. #SQlcruise')
INSERT INTO #testData (person, tweets) VALUES ('Grant Fritchey @Gfritchey','I see @AaronBertrand and @sqlrnnr #SQLcruise')
INSERT INTO #testData (person, tweets) VALUES ('Grant Fritchey @Gfritchey','I''m at Plaça de Sant Felip Neri in Barcelona https://www.swarmapp.com/c/7hWHjnWOAt8 ')
INSERT INTO #testData (person, tweets) VALUES ('Grant Fritchey @Gfritchey','I''m at Xaloc in Barcelona, Catalonia https://www.swarmapp.com/c/h4856sB1K8O ')
INSERT INTO #testData (person, tweets) VALUES ('Grant Fritchey @Gfritchey','Interesting reading: Haunting chalkboard drawings, frozen in time for 100 years, discovered in Oklahoma school http://buff.ly/1f4R5cs ')
INSERT INTO #testData (person, tweets) VALUES ('Grant Fritchey @Gfritchey','Interesting reading: It’s The Future http://buff.ly/1Qr1aRI ')
INSERT INTO #testData (person, tweets) VALUES ('Grant Fritchey @Gfritchey','Interesting reading: The Curious Case of Mencius Moldbug http://buff.ly/1cNmRJn ')
INSERT INTO #testData (person, tweets) VALUES ('Grant Fritchey @Gfritchey','Still in port, but I finished my first presentation. #sqlcruise is off and running.')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','My connection is now leaving earlier than originally scheduled.')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','I''m so confused. ')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','I wish I had some UA statuse friends who could call and see if I was rebooked yet or not')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','Now another 1.5 hour delay #karenstravelstories')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','Not sure this math works out for YYZ > ORD > MSP http://ift.tt/1MEZWMH ')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','Stayed on tarmac for an hours. Now back to gate to get more fuel. http://ift.tt/1HKjsId ')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','Dear @united I sent you a DM love note.')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','So we took since tour of the Tarmac, now headed back to gate to get more fuel. #karenstrav… http://ift.tt/1C8SrrH ')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','Now a ground stop at ORD. so no take off time now. # karenstravelstories. Connections at risk.')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','Both of these made me laugh. #dataquality ')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','Wow. Now United is serving Prosecco on domestic flights. Better than the Na in breakfast salad.')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','The crew doesn''t like being handed a plane full of kicked in the junk passengers.')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','Oh. So I turns out the crew was still at the gate when the GA made her announcement. They are not happy either')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','I feel like an idiot with a Mac every time I go to touch the IFE on a UA flight. #ItsNotTouch')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','I would have volunteered. But only other option has no F.')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','Nearly all the pax are saying "oh. It''s our fault?" I think she made a lot of non-cooperative pax here. #karenstravelstories')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','Due to the fact we aren''t getting any volunteers to take another flight, we are going to delay the flight. Really @united? Nasty tone')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','I''m posting odds that he elbows past me at boarding time.')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','He also has a white canvas tote, à la LLBean.')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','I ant to ask if he works for JCREW')
INSERT INTO #testData (person, tweets) VALUES ('Karen Lopez @datachick ','I''m judging the guy next to me by how he is dressed. I think he must be a real jerk. ')
SET @subject = 'Twitter Status Report' --Subject line of the email
--Load @Table which isn't really a table with your data
SELECT @Table = @Table + '<tr style="background-color:#A3E0FF;">' +
'<td>' + person + '</td>' +
'<td>' + CAST(COUNT(tweets) AS VARCHAR(5)) + '</td>'
FROM #testData
GROUP BY person
ORDER BY COUNT(tweets) DESC
SET @tableHTML =
N'<H3><font color="Red">Who''s the top tweeter?</H3>' + --Title above the table
N'<table border="1" align="left" cellpadding="2" cellspacing="0" style="color:purple; font-family:helvetica; text-align:center;" >' + --Table formatting
N'<tr style ="font-size: 14px; font-weight: normal; background: #b9c9fe; text-align:left;"> ' + --Row level formatting
N'<th>Twitter celebrity</th><th>Number of Tweets</th>' + --Row titles
N'</tr>' + @Table + N'</table>' --Row data
So many infograms, charts and reports are a waste of bytes or worse a waste of paper they are printed on. At least manure can be used as fertilizer. Bad BI is useless, wasteful and potentially dangerous. So much gets produced without well reasoned thought and without involving the people in the business this “intelligence” is produced for.
Titans of industry met last Friday night, 3 engineers and 1 IT geek at a table of tacos, margaritas and beer. What started off as friendly shop talk soon escalated into rants about the uselessness of various BI outputs. One described a hallway, walls lined with plastic sleeves filled with reports that no one read. Another talked about a business, its physical infrastructure crumbling, that poured countless hours into producing acronymed filled graphs. I offered my own story.
Just out of college, MBA degree freshly embossed, a love for statistical analysis and a brand new job I was eager to impress at, I worked to create a gargantuan monthly reporting package. It was Excel based. It was overly complicated and cumbersome. It contained graphs and charts based on incomplete data and did not answer any questions asked by those who really knew the company’s business. My boss was very excited and supportive. He thought this was vital information and had been badly needed. I’m certain he never finished reading the 1st month’s report and stopped looking at them altogether after a while. I soldiered on, determined to prove my worth. I was not providing value to the company, but I did learn a valuable lesson. Business intelligence, or whatever name your analysis goes by, is only as useful as the questions it is able to answer and the decisions you can make based on it.
BI, big data, analytics, etc are amazing, exciting and hot selling items right now. Like all hot selling and popular items it’s buyer beware. Before you churn out that next bit of analysis that you think the business needs to have, ask yourself some questions.
What decision have you ever made off of a heat map?
What strategic objective have you achieved because of a word cloud?
Who in the business has asked for that report and what question/problem is it solving?
Producing unneeded or not useful reporting not only wastes your time, but everyone else in the organization who comes across it. Time wasting is probably the least of your worries. If the data you are reporting on isn’t good in the first place you might be damning a generation to a lifetime of spinach. Phil Factor can make that point much better than I.
I am a giant hypocrite in this area. My own site, http://www.beerintelligenceproject.com, is dedicated to creating, storing and reporting on data for no other purpose than for my personal enjoyment. There’s a heat map based on count of breweries and beers and a top 10 breweries by beer chart. I don’t have a word cloud, but if I did there would be a giant IPA in the middle. This BI is crap, but nobody is paying me to produce it.
Do DBA’s fear change? I sure hope not because it’s coming. Be it DevOps or cloud services or your deep love for SQL Server 2000; platforms, services and your way of life will shift. I like installing new versions of SQL Server, checking out the changes and new features. I can’t say I always embrace the change and SQL Server 2014 is a mix of the comfortable familiar and the new (and maybe not for me yet) frontier. SQL Server 2014 has its feet on the edge of my lawn and I’m trying to figure out if I should start yelling at it yet.
Last week I had my first opportunity to install SQL Server 2014 on a new to me OS, Windows 2012. The SQL installation process was very familiar and changed little from 2012. It still started at the Installation Center and offered a near identical set on the Features page with the difference is the missing SQL Server Data Tools. In 2012 you had the option of installing the SQL Server development environment, including what was once called BIDS, Business Intelligence Development Studio. The 2014 install doesn’t have this option as it has been split and must be downloaded separately, Microsoft SQL Server Data Tools – Business Intelligence for Visual Studio 2013.
Miss you? I didn’t even realize you were gone!
The rest of the installation was very familiar with no surprises. There was this nice reminder on setting permissions for the default backup directory, just in case you forgot to do this. I don’t recall seeing this in 2012.
An actual permissions check would be better than a blanket warning.
Backups in 2014 have some new enhancements for your backup location and letting SQL Server manage your backups and. Taking some screenshots from the good old maintenance plans, you can see on the Destination tab that along with the Folder (local or network) you now have the option of an Azure storage container.
Where are your back ups going to go?
Managing backups depending on scale can be a pretty trivial to overwhelming job. My experiences with backups has been more on the side of trivial. Not to make light of the importance of backups, it just hasn’t taken much of my time. Those with with a more difficult job of managing backups may be interested in turning over responsibility to SQL Server. With the the new SQL Server Managed Backup to Windows Azure, SQL Server manages and automates the backups to the Azure Blob. With this setup the DBA is only required provide the retention period settings and the storage location with SQL Server determining the frequency based on the workload. I can see the appeal of turning this over to SQL Server to manage.
Full Database Backup:SQL Server Managed Backup to Windows Azure agent schedules a full database backup if any of the following is true.
A database is SQL Server Managed Backup to Windows Azure enabled for the first time, or when SQL Server Managed Backup to Windows Azure is enabled with default settings at the instance level.
The log growth since last full database backup is equal to or larger than 1 GB.
The maximum time interval of one week has passed since the last full database backup. TP – 1 week! None of my database have a full backup that infrequently, especially when differentials aren’t supported. See below for support.
The log chain is broken. SQL Server Managed Backup to Windows Azure periodically checks to see whether the log chain is intact by comparing the first and last LSNs of the backup files. If there is break in the log chain for any reason, SQL Server Managed Backup to Windows Azure schedules a full database backup. The most common reason for log chain breaks is probably a backup command issued using Transact-SQL or
through the Backup task in SQL Server Management Studio. Other common scenarios include accidental deletion of the backup log files, or accidental overwrites of backups. TP – This is a pretty sweet feature. I can see other people having cases where someone (maybe a developer, just maybe) with too many permissions takes a back up. That’s never happened to me, just saying.
Transaction Log Backup:SQL Server Managed Backup to Windows Azure schedules a log backup if any of the following is true:
There is no log backup history that can be found. This is usually true when SQL Server Managed Backup to Windows Azure is enabled for the first time. TP – Starting thing off right, I like that.
The transaction log space used is 5 MB or larger. TP – How many changes were made in your database before 5 MB were written to the log? Is it OK to lose those?
The maximum time interval of 2 hours since the last log backup is reached. TP – Longer interval than most of my t-log backups, but at least it isn’t a week.
Any time the transaction log backup is lagging behind a full database backup. The goal is to keep the log chain ahead of full backup. TP – We all need goals.
Limitations:
SQL Server Managed Backup to Windows Azure agent supports database backups only: Full and Log Backups. File backup automation is not supported.
System Databases are not supported. TP – SQL Server can’t manage everything, I guess you still have a job.
Windows Azure Blob Storage service is the only supported backup storage option. Backups to disk or tape are not supported. TP – I guess that’s why they call it SQL Server Managed Backup to Windows Azure. Soon to be called SSMBWA, that rolls right off the tongue.
This is a change I’m not quite ready to embrace. I like control of my backups. I want to determine the frequency based off my discussions with the data owners, not on SQL Servers workload analysis. This feature isn’t allowed on my lawn.
You know who doesn’t fear change, but actively seeks it out and promotes it? Mercy Corps, be the change and help in needed places like Nepal.